first-class llama.cpp · Vulkan + FLM (NPU)
Strix Halo / Ryzen AI Max+
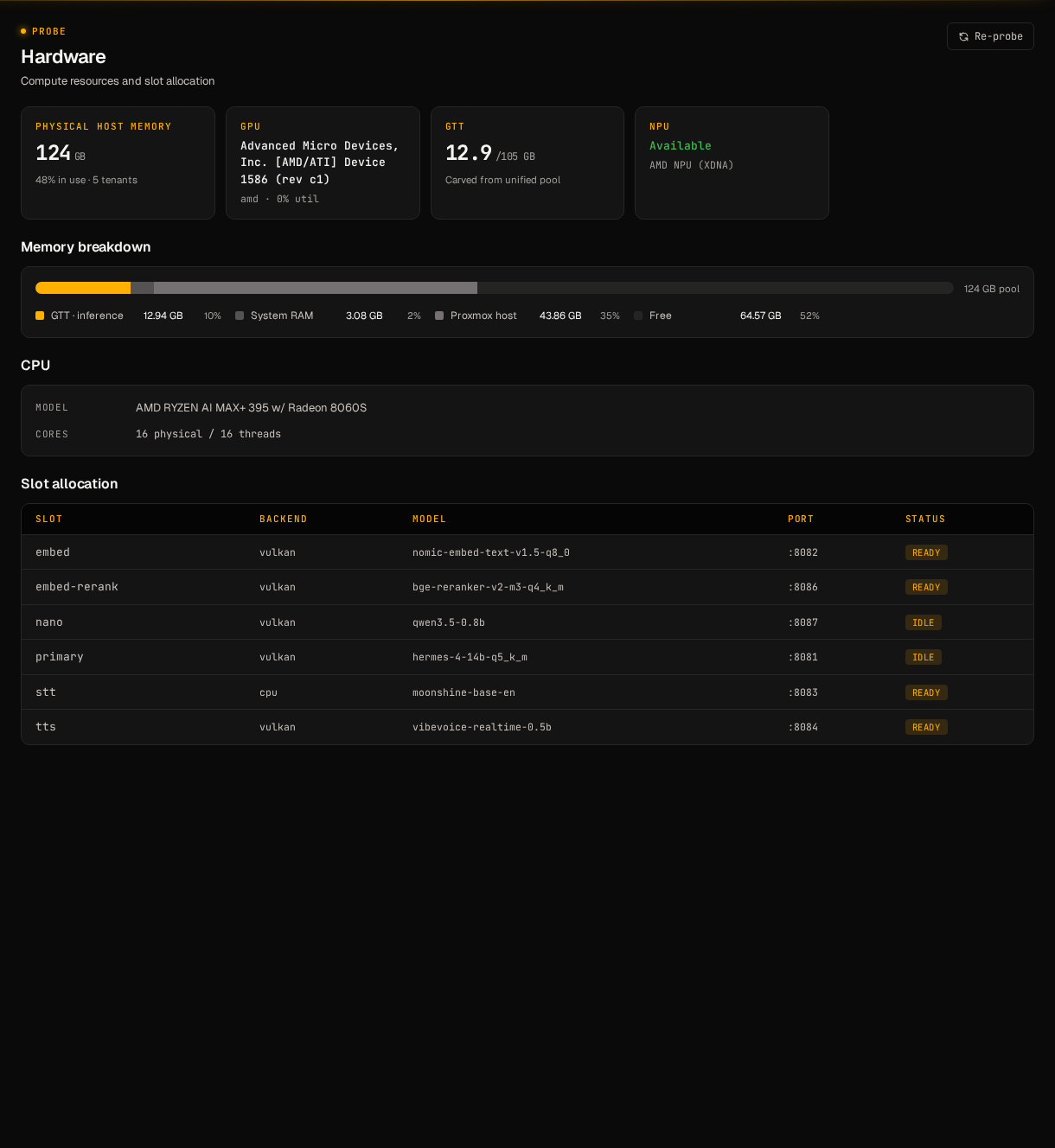
The reference deployment. APU + XDNA NPU + a single unified
memory pool. The iGPU carveout is BIOS-tunable up to
~96 GB on 128 GB SKUs, and the slot lifecycle and
FLM provider were written against this hardware first. FLM
is live with a self-contained
ghcr.io/hal0ai/hal0-toolbox-flm:v1
image; chat + embed are surfaced in the picker when XDNA
and the toolbox image are both present. STT slice deferred.
Verified on Ryzen AI Max iGPU + Vulkan: Qwen 0.5B 217–413 tok/s; Phi-3 Mini Q4 ~71 tok/s, ~280 ms round-trip; concurrent primary + embed ~258 tok/s, <200 ms dispatch. NPU tok/s measurements pending (manifest digest still null).
- Ryzen AI Max+ 395 (128 GB)
- Ryzen AI Max 385 / 390 (64 GB)