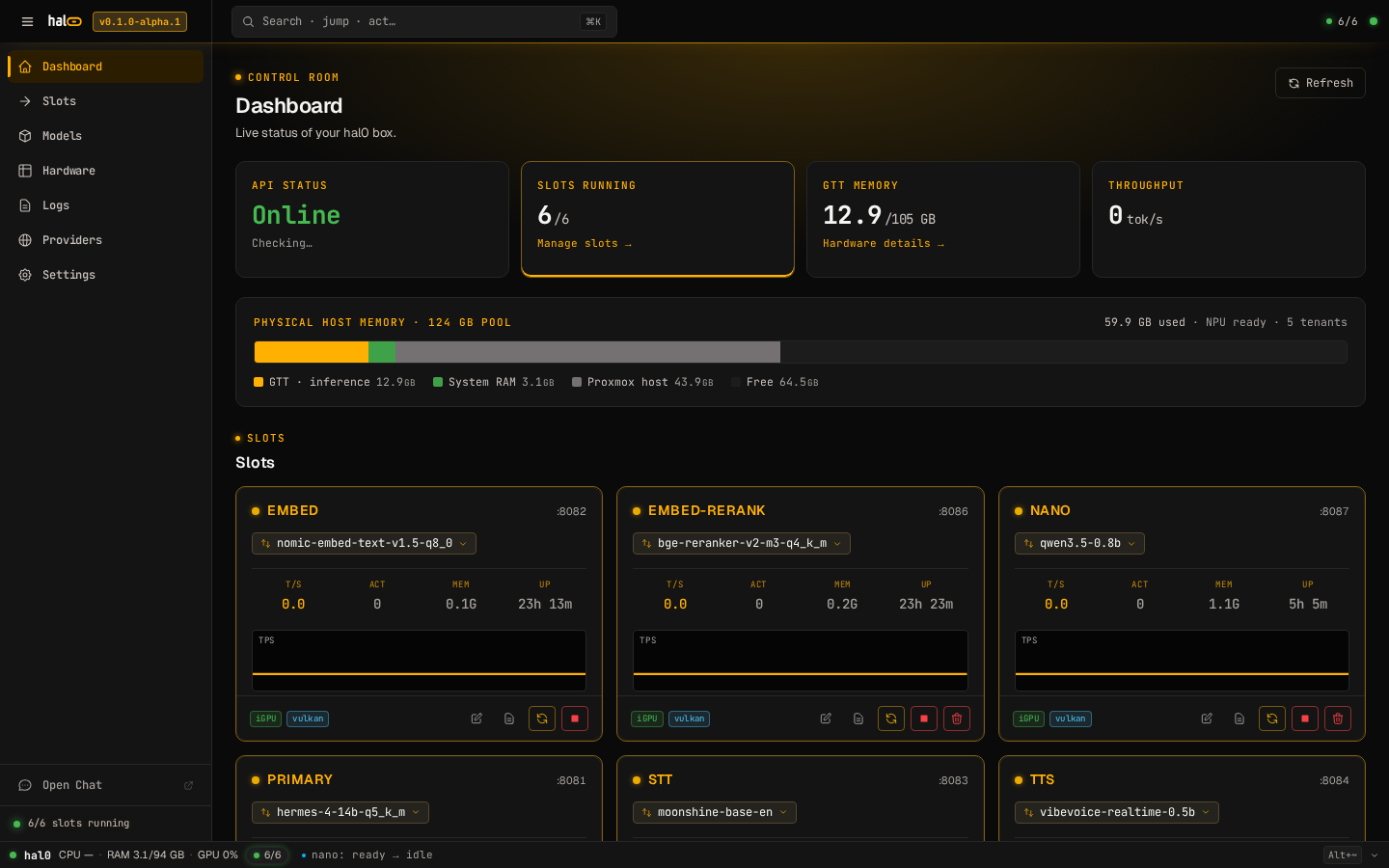
hal0 isn't an inference engine. It's the orchestration,
lifecycle, and multi-modal surface around llama.cpp, FLM,
Moonshine, and Kokoro. Honest take, in one table.
vs. ollama.
systemd-managed slots survive
hal0-api restarts. The OpenAI
surface includes embeddings, rerank,
and STT/TTS, not only chat. Hardware probe and slot
fit warnings are first-class.
vs. LM Studio.
Linux-first, headless-first, one-line install, no GUI
required. Prewired OpenWebUI handles chat; the dashboard is
for operating the box.
vs. raw llama.cpp.
hal0 owns the lifecycle: health probes, atomic env writes,
cold-boot grace, single-flight prefetch, structured errors,
signed self-update with rollback.
vs. cloud APIs.
Your hardware, your data, your models. External upstreams
(OpenRouter, Anthropic, OpenAI, custom) can be configured as
fallbacks behind the same /v1/*
surface, so you can mix local and remote per-model in one config.